Friday
Nov202015
Automater Update .21
Keeping Automater up to date:
Download the latest version: https://github.com/1aN0rmus/TekDefense-Automater
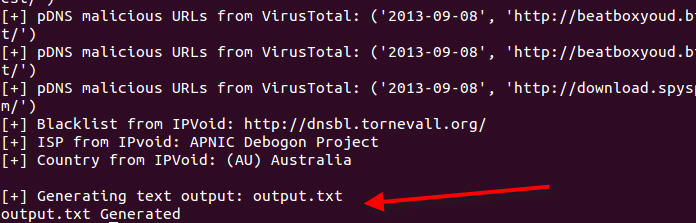
One of the more outstanding modifications added to version .21 of Automater is that users no longer need to worry about keeping on top of the GitHub site to ensure all of the python modules are the latest version. With a small addition of a –Vv in the command line arguments, Automater will check if the local python modules match the modules on the TekDefense Automater GitHub site. The –V (--vercheck) argument is actually the argument that tells Automater to check the modules, and the small –v (--verbose) is required to make Automater report the outcome. If the files don’t match, Automater will send a notification to stdout to alert the user to which module has been modified, so up to date modules can be pulled if the user wants. The –v (--verbose) option can be used to turn on or off any information sent to stdout to either silence or allow Automater to talk to stdout.

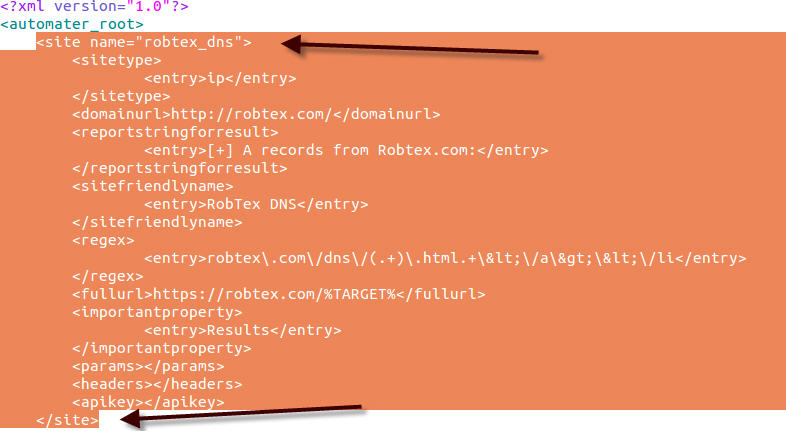
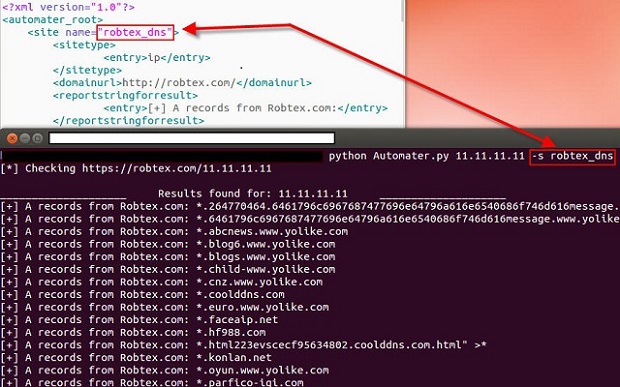
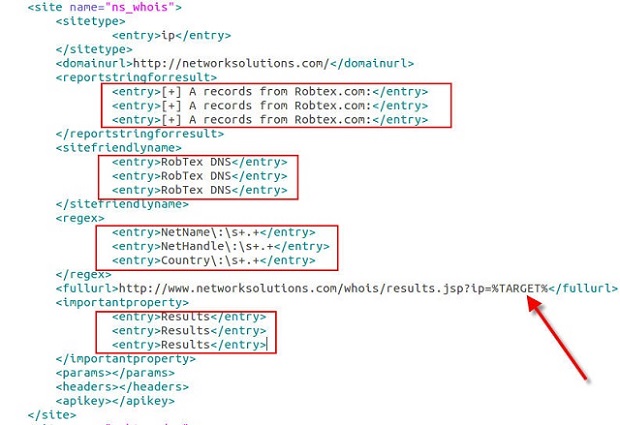
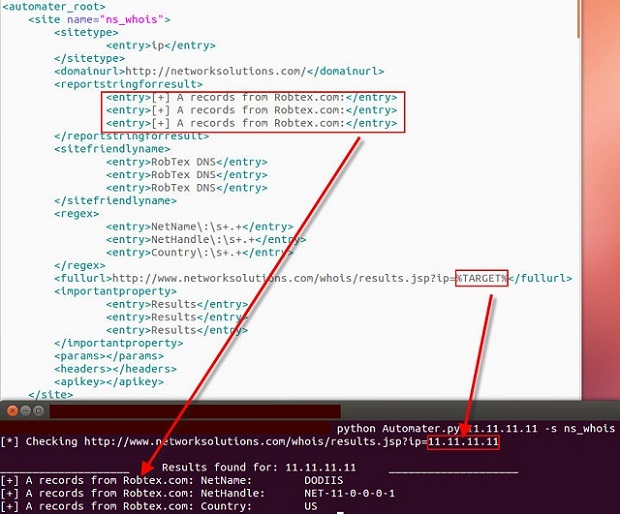
Arguably an even better option added is yet another “version” check of sorts. The sites.xml file is still required locally so that Automater can get instructions on what sites to check and what regexs to report upon. However, a new tekdefense.xml file is also checked for and utilized if it is found locally. The significance of this is that with a –r (--refreshxml) switch included in the command line argument call, Automater will check the TekDefense Automater GitHub site and pull the tekdefense.xml file for use. If the –r switch is utilized, and the local tekdefense.xml file is found to be different on the local machine, the modified (updated) file on GitHub will be pulled and utilized. This ensures that you have the ability to do your own calls with the sites.xml file, while ALSO maintaining constant calls to sites and checks utilized by the TekDefense crew. Together this gives the Automater use the best coverage with no modifications required or manual processes followed.

New Requirements and what they mean:
The new Automater has several updates. Out of the blocks, the requests module (version 2.7 or above) is now required to run Automater. For instructions on getting the requests module if you don't already have view http://docs.python-requests.org/en/latest/user/install/. This gives us better control of returning HTML and sets us up for further upgrades in the near future when we begin using JSON APIs and data collecting capabilities – more on this as things progress. Using requests, the default timeout of get calls to web sites has now been set to 5 seconds. This allows Automater to move on after 5 seconds of waiting for a response from a web site. However, if a web site does respond and provide some input, but the site is slow in its response time, the get request will not timeout. This timeout is only for those sites that just don’t respond. Further refinements on this subject will continue in future upgrades. There are several bug fixes and other modifications and we will soon thread Automater to provide better response times. For instance the delay feature was fixed.
.\Automater.py -husage: Automater.py [-h] [-o OUTPUT] [-b] [-f CEF] [-w WEB] [-c CSV][-d DELAY] [-s SOURCE] [--proxy PROXY] [-a USERAGENT] [-V][-r] [-v]targetIP, URL, and Hash Passive Analysis toolpositional arguments:target List one IP Address (CIDR or dash notation accepted),URL or Hash to query or pass the filename of a filecontaining IP Address info, URL or Hash to query eachseparated by a newline.optional arguments:-h, --help show this help message and exit-o OUTPUT, --output OUTPUTThis option will output the results to a file.-b, --bot This option will output minimized results for a bot.-f CEF, --cef CEF This option will output the results to a CEF formattedfile.-w WEB, --web WEB This option will output the results to an HTML file.-c CSV, --csv CSV This option will output the results to a CSV file.-d DELAY, --delay DELAYThis will change the delay to the inputted seconds.Default is 2.-s SOURCE, --source SOURCEThis option will only run the target against aspecific source engine to pull associated domains.Options are defined in the name attribute of the siteelement in the XML configuration file. This can be alist of names separated by a semicolon.--proxy PROXY This option will set a proxy to use (eg.proxy.example.com:8080)-a USERAGENT, --useragent USERAGENTThis option allows the user to set the user-agent seenby web servers being utilized. By default, the user-agent is set to Automater/version-V, --vercheck This option checks and reports versioning forAutomater. Checks each python module in the Automaterscope. Default, (no -V) is False-r, --refreshxml This option refreshes the tekdefense.xml file from theremote GitHub site. Default (no -r) is False.-v, --verbose This option prints messages to the screen. Default (no-v) is False.
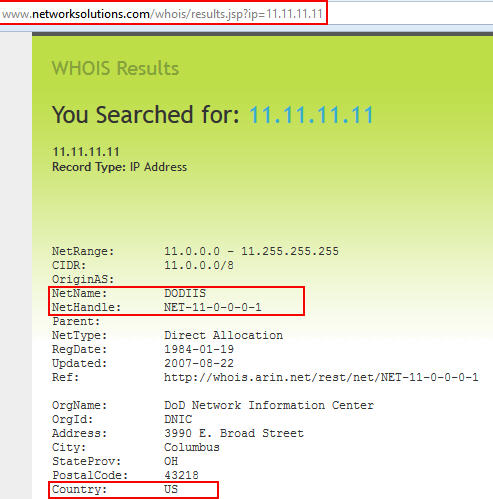
Specific sites (already in the sites.xml or tekdefense.xml file) can be called in case the user only wants responses from specific sites. While previous versions of Automater allowed this function for one site using the –s (--source) switch, the new version allows multiple sites to be utilized by separating the required sites with a semicolon. So in the past, if the user had a sites.xml file with the totalhash_ip entry, the user could call Automater with –s totalhash_ip and only receive information about totalhash. However, if the user now wants more than totalhash output, but not all information in the sites.xml or tekdefense.xml file(s), he could enter something like Automater –s totalhash_ip;robtex to get totalhash and robtex information. Any site within the sites.xml or tekdefense.xml ca be joined in this way using the semicolon separator between sites.

Lastly, there is now a bot output mode for those who want friendlier output for bots. For instance here is the output using Automater with -b in a skype bot.

 Admin
Admin